Data exploration
Perform a first quality-check of your data and get an overview of the full trial in a glimpse with automatically generated, interactive, fully customizable plots covering PK dynamics and relations between covariates.
Non Compartmental analysis of PK datasets
The first main feature of PKanalix is the calculation of the parameters in the Non Compartmental Analysis framework.
This task requires defining rules for the calculation of the λz(slope of the terminal elimination phase) to be able to compute the NCA parameters. This definition can be done either globally via rules (e.g adjusted R2 or time window) or on each individual where the user can choose or remove any point for the calculation.
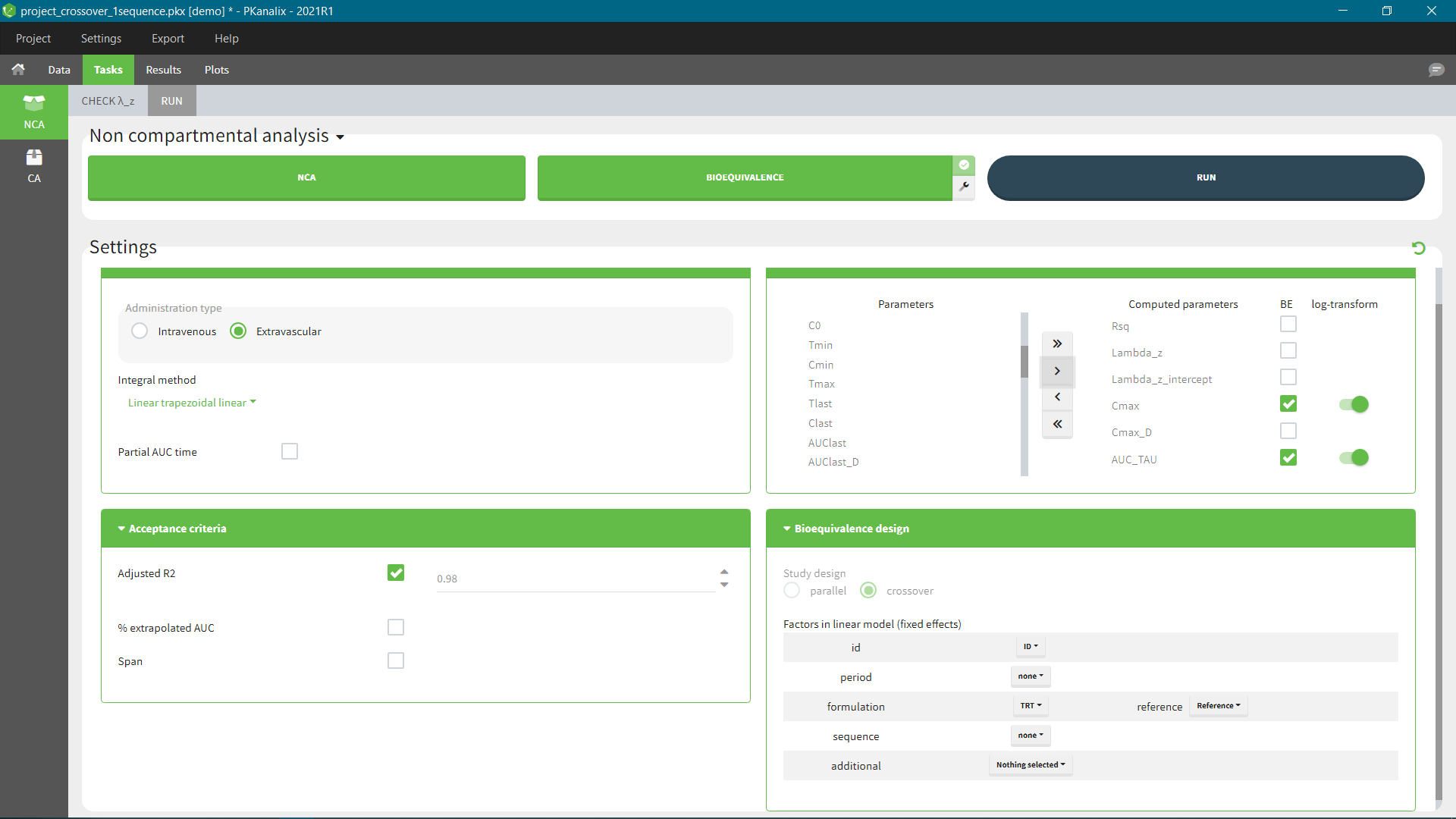
Bioequivalence study
The average NCA parameters obtained for different groups (e.g a test and a reference formulation) can be compared using the Bioequivalence task. Linear model definition contains one or several fixed effects selected in an integrated module. It allows to obtain a confidence interval compared to the predefined BE limits and automatically displayed in intuitive tables and plots.
Compartmental Analysis of PK datasets
The second main feature of PKanalix is the calculation of the parameters in the Compartmental Analysis framework. It consists in finding parameters of a PK model representing the kinetics in compartments for each individual. Automatic initialization is performed for a better convergence of each parameter for each individual.
This task defines a structural model (based on a user-friendly PK models library) and estimates the parameters for all the individuals. Automatic initialization method improves the convergence of parameters for each individual.
Outputs and plots
All NCA and/or CA outputs are displayed in sortable formatted tables easy to copy to any document, and exported in the result folder in an R-compatible format. Interactive plots are also generated for straightforward interpretation of the results.
R API to automate your process
All steps performed in PKanalix can be run from R with the LixoftConnectors package. What you have done once intuitively in the interface on a specific dataset can be generalized to a script automating the process for any other dataset.
Integration of your NCA/CA projects to the Modeling & Simulation & Trial Design workflow
Use the same data file for all your analyses – Data exploration, NCA, CA, Population Modeling. PKanalix alone does not include population analysis. However, exporting your PKanalix projects to Monolix will speed up your population modeling since it automatically sets everything you need in Monolix to run parameter estimation in a population modeling framework in a click: interpreted dataset, structural model, initial values do not need to be redefined. Importing formatted datasets from clinical trials simulated in Simulx is also possible to post-process your outputs and analyse trials with your favorite NCA parameters.
Comprehensive documentation and examples
Great care has been taken to provide the user with a comprehensive PKanalix documentation that includes methodology, software manuals and tutorials.
A wide collection of examples that include models and data can be used as templates to start your own project.
A lot of online material (feature of the weeks, webinars, …) on our Lixoft University page.